Monday, 27 March 2017
How to dump scheduling graph?
78. How to dump scheduling graph?
/home/jtony/git-llvm/build/team-llvm/bin/llc /home/jtony/scrum/s11/memcpy/jtony/ppc.ll -view-misched-dags 2>&1 | /home/sfertile/bin/capture_dot
test/CodeGen/PowerPC/reduced.ll
79. How to show hidden llc options?
llc -help-hidden
like:
-view-misched-dags - Pop up a window to show MISched dags after they are processed
-view-sched-dags - Pop up a window to show sched dags as they are processed
-view-sunit-dags - Pop up a window to show SUnit dags after they are processed
Sunday, 26 March 2017
What is llvm-dis?
The llvm-dis command is the LLVM disassembler. It takes an LLVM bitcode file and converts it into human-readable LLVM assembly language.
If the input is being read from standard input, then llvm-dis will send its output to standard output by default. Otherwise, the output will be written to a file named after the input file, with a
.ll suffix added (any existing .bc suffix will first be
removed). You can override the choice of output file using the
-o option.
Saturday, 25 March 2017
迭代文件中的行、单词和字符
1. 迭代文件中的每一行
- while 循环法
while read line;doecho $line;done < file.txt
改成子shell:
cat file.txt | (while read line;do echo $line;done)
- awk法:
cat file.txt| awk '{print}'
2.迭代一行中的每一个单词
for word in $line;doecho $word;done
3. 迭代每一个字符
${string:start_pos:num_of_chars}:从字符串中提取一个字符;(bash文本切片)
${#word}:返回变量word的长度
for((i=0;i<${#word};i++))doecho ${word:i:1);done
[URL=http://www.visitormap.org/][IMG]http://www.visitormap.org/map/m:bekbxjyftgtbwlff/s:1/c:ffffff/p:dot/y:0.png[/IMG][/URL]
Thursday, 23 March 2017
LDUX/ldux ( Load Doubleword with Update Indexed)
Load Doubleword with Update Indexed
X-form
ldux RT,RA,RB
31 RT RA RB 53 /
0 6 11 16 21 31
EA <= (RA) + (RB)
RT <= MEM(EA, 8)
RA <= EA
Let the effective address (EA) be the sum (RA)+ (RB).
The doubleword in storage addressed by EA is loaded
into RT.
EA is placed into register RA.
If RA=0 or RA=RT, the instruction form is invalid.
Special Registers Altered:
None
D-Form VS X-Form
20. D-Form VS X-Form
D-Form is the immediate/register addressing mode.
X-Form is the register/register addressing mode.
Otherwise known as unindexed and indexed loads respectivelly
So if you have a series consecutive loads, the D-Form loads have a huge advantage.
Because with X-Form loads you have to have the offset in a register so you get consecutive
offsets by either using multiple registers or having instructions in between to increment the offset.
D-Form is the immediate/register addressing mode.
X-Form is the register/register addressing mode.
Otherwise known as unindexed and indexed loads respectivelly
So if you have a series consecutive loads, the D-Form loads have a huge advantage.
Because with X-Form loads you have to have the offset in a register so you get consecutive
offsets by either using multiple registers or having instructions in between to increment the offset.
call back function
C Callbacks
Callbacks have a wide variety of uses, for example in error signaling: a Unix program might not want to terminate immediately when it receives SIGTERM, so to make sure that its termination is handled properly, it would register the cleanup function as a callback. Callbacks may also be used to control whether a function acts or not: Xlib allows custom predicates to be specified to determine whether a program wishes to handle an event.The following C code demonstrates the use of callbacks to display two numbers.
#include <stdio.h>
#include <stdlib.h>
/* The calling function takes a single callback as a parameter. */
void PrintTwoNumbers(int (*numberSource)(void)) {
printf("%d and %d\n", numberSource(), numberSource());
}
/* A possible callback */
int overNineThousand(void) {
return (rand()%1000) + 9001;
}
/* Another possible callback. */
int meaningOfLife(void) {
return 42;
}
/* Here we call PrintTwoNumbers() with three different callbacks. */
int main(void) {
PrintTwoNumbers(&rand);
PrintTwoNumbers(&overNineThousand);
PrintTwoNumbers(&meaningOfLife);
return 0;
}
125185 and 89187225 9084 and 9441 42 and 42
From
知乎
作者:桥头堡
链接:https://www.zhihu.com/question/19801131/answer/27459821
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/19801131/answer/27459821
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么是回调函数?
我们绕点远路来回答这个问题。
编程分为两类:系统编程(system programming)和应用编程(application programming)。所谓系统编程,简单来说,就是编写库;而应用编程就是利用写好的各种库来编写具某种功用的程序,也就是应用。系统程序员会给自己写的库留下一些接口,即API(application programming interface,应用编程接口),以供应用程序员使用。所以在抽象层的图示里,库位于应用的底下。
当程序跑起来时,一般情况下,应用程序(application program)会时常通过API调用库里所预先备好的函数。但是有些库函数(library function)却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务。这个被传入的、后又被调用的函数就称为回调函数(callback function)。
打个比方,有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。这里,“叫醒”这个行为是旅馆提供的,相当于库函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作,也就是把回调函数传入库函数的动作,称为登记回调函数(to register a callback function)。如下图所示(图片来源:维基百科):
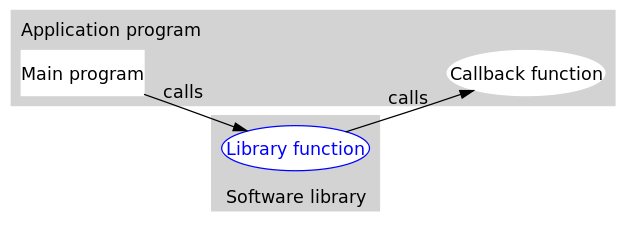
可以看到,回调函数通常和应用处于同一抽象层(因为传入什么样的回调函数是在应用级别决定的)。而回调就成了一个高层调用底层,底层再回过头来调用高层的过程。(我认为)这应该是回调最早的应用之处,也是其得名如此的原因。
我们绕点远路来回答这个问题。
编程分为两类:系统编程(system programming)和应用编程(application programming)。所谓系统编程,简单来说,就是编写库;而应用编程就是利用写好的各种库来编写具某种功用的程序,也就是应用。系统程序员会给自己写的库留下一些接口,即API(application programming interface,应用编程接口),以供应用程序员使用。所以在抽象层的图示里,库位于应用的底下。
当程序跑起来时,一般情况下,应用程序(application program)会时常通过API调用库里所预先备好的函数。但是有些库函数(library function)却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务。这个被传入的、后又被调用的函数就称为回调函数(callback function)。
打个比方,有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。这里,“叫醒”这个行为是旅馆提供的,相当于库函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作,也就是把回调函数传入库函数的动作,称为登记回调函数(to register a callback function)。如下图所示(图片来源:维基百科):
可以看到,回调函数通常和应用处于同一抽象层(因为传入什么样的回调函数是在应用级别决定的)。而回调就成了一个高层调用底层,底层再回过头来调用高层的过程。(我认为)这应该是回调最早的应用之处,也是其得名如此的原因。
LXVD2X/lxvd2x (Load VSX Vector Doubleword*2 Indexed)
Load VSX Vector Doubleword*2 Indexed
X-form
lxvd2x XT,RA,RB
31 T RA RB 844 TX
0 6 11 16 21 31
if MSR.VSX=0 then VSX_Unavailable()
EA <= RA=0 ? GPR[RB] : GPR[RA] + GPR[RB]
VSR[32×TX+T].dword[0] <= MEM(EA, 8)
VSR[32×TX+T].dword[1] <= MEM(EA+8, 8)
Let XT be the value 32×TX + T.
Let EA be the sum of the contents of GPR[RA], or 0 if RA
is equal to 0, and the contents of GPR[RB].
For each integer value i from 0 to 1, do the following.
When Big-Endian byte ordering is employed, the
contents of the doubleword in storage at address
EA+8×i are placed into load_data in such an order
that;
– the contents of the byte in storage at address
EA+8×i are placed into byte element 0 of
load_data,
– the contents of the byte in storage at address
EA+8×i+1 are placed into byte element 1 of
load_data, and so forth until
– the contents of the byte in storage at address
EA+8×i+7 are placed into byte element 7 of
load_data.
When Little-Endian byte ordering is employed, the
contents of the doubleword in storage at address
EA+8×i are placed into load_data in such an order
that;
– the contents of the byte in storage at address
EA+8×i are placed into byte element 7 of
load_data,
– the contents of the byte in storage at address
EA+8×i+1 are placed into byte element 6 of
load_data, and so forth until
X-form
lxvd2x XT,RA,RB
31 T RA RB 844 TX
0 6 11 16 21 31
if MSR.VSX=0 then VSX_Unavailable()
EA <= RA=0 ? GPR[RB] : GPR[RA] + GPR[RB]
VSR[32×TX+T].dword[0] <= MEM(EA, 8)
VSR[32×TX+T].dword[1] <= MEM(EA+8, 8)
Let XT be the value 32×TX + T.
Let EA be the sum of the contents of GPR[RA], or 0 if RA
is equal to 0, and the contents of GPR[RB].
For each integer value i from 0 to 1, do the following.
When Big-Endian byte ordering is employed, the
contents of the doubleword in storage at address
EA+8×i are placed into load_data in such an order
that;
– the contents of the byte in storage at address
EA+8×i are placed into byte element 0 of
load_data,
– the contents of the byte in storage at address
EA+8×i+1 are placed into byte element 1 of
load_data, and so forth until
– the contents of the byte in storage at address
EA+8×i+7 are placed into byte element 7 of
load_data.
When Little-Endian byte ordering is employed, the
contents of the doubleword in storage at address
EA+8×i are placed into load_data in such an order
that;
– the contents of the byte in storage at address
EA+8×i are placed into byte element 7 of
load_data,
– the contents of the byte in storage at address
EA+8×i+1 are placed into byte element 6 of
load_data, and so forth until
How to use bugpoint reduce a IR test case?
(1) Find the temp files created by clang in the crash report. Usually, it is at the end of the crash report, which
points to a file in the /tmp/ directory. for example:
clang-5.0: note: diagnostic msg: /tmp/tsan_mutexset-bb0974.cpp
clang-5.0: note: diagnostic msg: /tmp/tsan_mutexset-bb0974.sh
(2) add '-S -emit-llvm -o tony.ll' to the script (tsan_mutexset-bb0974.sh in this example) to produce an .ll file.
(3) Then you write a simple script like this:
```#!/bin/bash
<broken-llc> $1 2>&1 | grep "<text of the assertion>" > /dev/null
if [[ $? -eq 0 ]]
then
exit 1
else
exit 0
fi
examples:
$ cat reduceScript.sh
```#!/bin/bash
/home/jtony/llvm/build/memcpyBootstrapSeanPatch/bin/llc $1 2>&1 | grep "Node emitted out of order - late" > /dev/null
if [[ $? -eq 0 ]]
then
exit 1
else
exit 0
fi
jyj14ibm
(4)run the following to reduce the given *.ll file once you have both the IR file (tony.ll) and the script (reduceScript.sh):
`$ bugpoint -compile-custom -compile-command=reduceScript.sh tony.ll`
(5) Use llvm-dis to generate the eventual reduced IR (*.ll) file from the bitcode file (*.bc).
For example:
llvm-dis bugpoint-reduced-simplified.bc
Feel free to update this initial bugpoint document.
points to a file in the /tmp/ directory. for example:
clang-5.0: note: diagnostic msg: /tmp/tsan_mutexset-bb0974.cpp
clang-5.0: note: diagnostic msg: /tmp/tsan_mutexset-bb0974.sh
(2) add '-S -emit-llvm -o tony.ll' to the script (tsan_mutexset-bb0974.sh in this example) to produce an .ll file.
(3) Then you write a simple script like this:
```#!/bin/bash
<broken-llc> $1 2>&1 | grep "<text of the assertion>" > /dev/null
if [[ $? -eq 0 ]]
then
exit 1
else
exit 0
fi
examples:
$ cat reduceScript.sh
```#!/bin/bash
/home/jtony/llvm/build/memcpyBootstrapSeanPatch/bin/llc $1 2>&1 | grep "Node emitted out of order - late" > /dev/null
if [[ $? -eq 0 ]]
then
exit 1
else
exit 0
fi
jyj14ibm
(4)run the following to reduce the given *.ll file once you have both the IR file (tony.ll) and the script (reduceScript.sh):
`$ bugpoint -compile-custom -compile-command=reduceScript.sh tony.ll`
(5) Use llvm-dis to generate the eventual reduced IR (*.ll) file from the bitcode file (*.bc).
For example:
llvm-dis bugpoint-reduced-simplified.bc
Feel free to update this initial bugpoint document.
Wednesday, 22 March 2017
awk 数据流处理工具 (b)
用样式对awk处理的行进行过滤
awk 'NR < 5' #行号小于5
awk 'NR==1,NR==4 {print}' file #行号1-4 (i.e, 1,2,3,4) 打印出来
awk 'NR==1;NR==4 {print}' file #行号1 and 4的打印出来
awk 'NR==1;NR==4 {print}' file #行号1 and 4的打印出来
awk '/linux/' #包含linux文本的行(可以用正则表达式来指定,超级强大,don't forget the two //)
awk '!/linux/' #不包含linux文本的行
设置定界符
使用-F来设置定界符(默认为空格)
awk -F: '{print $NF}' /etc/passwd
读取命令输出
使用getline,将外部shell命令的输出读入到变量cmdout中;
echo | awk '{"grep root /etc/passwd" | getline cmdout; print cmdout }'
在awk中使用循环
for (( i=2; i <= $max; ++i )); do echo "$i"; doneThe above is just a normal forloop.
TO INVESTIGATE
Tuesday, 21 March 2017
Variance and standard deviation
awk 数据流处理工具 (a)
- awk脚本结构
awk ' BEGIN{ statements } statements2 END{ statements } '
- 工作方式
1.执行begin中语句块;
2.从文件或stdin中读入一行,然后执行statements2,重复这个过程,直到文件全部被读取完毕;
3.执行end语句块;
print 打印当前行
- 使用不带参数的print时,会打印当前行;
echo -e "line1\nline2" | awk 'BEGIN{print "start"} {print } END{ print "End" }'
- print 以逗号分割时,参数以空格定界;
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; \print var1, var2 , var3; }'$>v1 V2 v3
- 使用-拼接符的方式(""作为拼接符);
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; \print var1"-"var2"-"var3; }'$>v1-V2-v3
特殊变量: NR NF $0 $1 $2
NR:表示记录数量,在执行过程中对应当前行号;
NF:表示字段数量,在执行过程总对应当前行的字段数;
$0:这个变量包含执行过程中当前行的文本内容; 当前行的所有内容。
$1:第一个字段的文本内容; 即第一列的内容。
$2:第二个字段的文本内容;即第二列的内容。
$3:第三个字段的文本内容;即第三列的内容。
... $n: 第n个字段的文本内容;即第n列的内容。
$3:第三个字段的文本内容;即第三列的内容。
... $n: 第n个字段的文本内容;即第n列的内容。
echo -e "line1 f2 f3\n line2 \n line 3" | awk '{print NR":"$0"-"$1"-"$2}'
- 打印每一行的第二和第三个字段:
awk '{print $2, $3}' file
- 统计文件的行数:
awk ' END {print NR}' file
- 累加每一行的第一个字段:
echo -e "1\n 2\n 3\n 4\n" | awk 'BEGIN{num = 0 ;print "begin";} {sum += $1;} END {print "=="; print sum }'
传递外部变量
var=1000echo | awk '{print vara}' vara=$var # 输入来自stdinawk '{print vara}' vara=$var file # 输入来自文件
Monday, 20 March 2017
summarizeSpecTimes.sh
Borrowed from Nemanja, need to learn.
#!/usr/bin/env bash
if [[ -z "$3" ]] # here -z means: True if string is empty. from 'help test' doc
then
echo "Usage: $0 -o <DIR> Baseline:<SPEC.out.csv> [<NAME>:<SPEC.out.csv> ...]"
echo
echo "This script creates a csv file that contains a summary of multiple SPEC"
echo "run result csv files. The baseline is assumed to be the very first file"
echo "passed in."
echo "The -o option is mandatory and must appear prior to the list of files."
echo
echo "Sample invocation:"
echo "$0 -o Summaries Baseline:CINT2006.110.ref.csv \\"
echo " Baseline:CFP2006.110.ref.csv NoCRBits:CINT2006.112.ref.csv \\"
echo " NoCRBits:CFP2006.112.ref.csv CheapBR:CINT2006.111.ref.csv \\"
echo " CheapBR:CFP2006.111.ref.csv"
echo
echo "Implementation detail: For processing the inputs, the script will"
echo "create a directory for each of the named runs which it will clean"
echo "up after. If this directory happens to contain directories of the"
echo "same name, the script will prompt you before overwriting them."
exit 1
fi
###########################SCRIPT BEGINS ON LINE 78#############################
function summarizeBench {
SUMMARY=""
if [ $(cat CurrBenchRunTimes.txt | wc -l) -eq 1 ]
then
cat CurrBenchRunTimes.txt CurrBenchRunTimes.txt > tmpCurrBenchRunTimes.txt
mv tmpCurrBenchRunTimes.txt CurrBenchRunTimes.txt
fi
while read RT
do
SUMMARY="$SUMMARY $RT"
done < CurrBenchRunTimes.txt
echo $1,$($SUMMARIZE -a $SUMMARY)
}
function summarizeIndividualFile {
START=0
PREV_BENCH=""
while IFS=, read BENCH REF_T RUN_T RATIO REST
do
if [ "$BENCH" = Benchmark ]
then
START=1
continue
fi
if [ $START -ne 1 ]
then
continue
fi
if echo $REST | grep ',NR,' > /dev/null
then
continue
fi
if [[ -z "$BENCH" ]]
then
summarizeBench $PREV_BENCH
break
fi
if [ "$BENCH" = "$PREV_BENCH" ]
then
echo $RUN_T >> CurrBenchRunTimes.txt
else
if [[ -n "$PREV_BENCH" ]]
then
summarizeBench $PREV_BENCH
fi
PREV_BENCH=$BENCH
echo $RUN_T > CurrBenchRunTimes.txt
fi
done < $FILE_TO_READ
}
function addNamedSummary {
echo "$(head -1 $OUTDIR/FinalSPECSummary.csv),$1(Median),$1(Best),$1(Worst),$1(%Variance),$1(%Diff(Median)),$1(%Diff(Best)),$1(%Diff(Worst))" > tmpSPECSummarizer.txt
cat $1/* | while IFS=, read BENCH MEDIAN BEST WORST VARIANCE
do
BASE_LINE=$(grep ^$BENCH $OUTDIR/FinalSPECSummary.csv)
BASE_MEDIAN=$(echo $BASE_LINE | cut -f2 -d,)
BASE_BEST=$(echo $BASE_LINE | cut -f3 -d,)
BASE_WORST=$(echo $BASE_LINE | cut -f4 -d,)
DIFF_MEDIAN=$($SUMMARIZE -d $BASE_MEDIAN $MEDIAN)
DIFF_BEST=$($SUMMARIZE -d $BASE_BEST $BEST)
DIFF_WORST=$($SUMMARIZE -d $BASE_WORST $WORST)
echo $(grep ^$BENCH $OUTDIR/FinalSPECSummary.csv),$MEDIAN,$BEST,$WORST,$VARIANCE,$DIFF_MEDIAN,$DIFF_BEST,$DIFF_WORST
done >> tmpSPECSummarizer.txt
mv tmpSPECSummarizer.txt $OUTDIR/FinalSPECSummary.csv
}
function cleanupIfNeeded {
grep $RUN_NAME SPECSummarizerDirectories.txt > /dev/null
UNSEEN_DIR=$?
if [ $UNSEEN_DIR -ne 0 ]
then
echo $RUN_NAME >> SPECSummarizerDirectories.txt
ls $RUN_NAME > /dev/null 2>&1
if [ $? -eq 0 ]
then
echo "Directory $RUN_NAME already exists. Overwrite (Y/N)?"
read ANS<&1
if echo "$ANS" | grep -i ^y
then
echo Overwriting...
rm -Rf $RUN_NAME
else
exit 1
fi
fi
fi
}
################################SCRIPT BEGINS###################################
if [ "$1" != "-o" ]
then
echo "The -o option is mandatory as the first argument."
exit 1
fi
shift
OUTDIR=$1
shift
ls $OUTDIR > /dev/null 2>&1 || mkdir $OUTDIR
if [[ $? -ne 0 ]]
then
echo "Unable to create directory '$OUTDIR' that you specified as the output directory."
exit 1
fi
# Build the summarizer executable
if which summarize >/dev/null 2>&1
then
SUMMARIZE=$(which summarize)
else
START_AT=$(grep -n '^#include' $0 | head -1 | cut -f1 -d:)
END_AT=$(cat $0 | wc -l)
CPROG_LINES=$(expr $END_AT - $START_AT)
((CPROG_LINES += 1))
tail -$CPROG_LINES $0 > /tmp/summarize.cpp
g++ /tmp/summarize.cpp -o summarize
if [[ $? -ne 0 ]]
then
rm -f /tmp/summarize.cpp
exit 1
fi
SUMMARIZE=./summarize
fi
rm -f SPECSummarizerDirectories.txt 2>/dev/null
# Summarize each of the individual files and put the summaries in separate dirs
while [[ -n "$1" ]]
do
touch SPECSummarizerDirectories.txt
FILE_TO_READ=${1#*:}
RUN_NAME=${1%:*}
cleanupIfNeeded
mkdir $RUN_NAME 2>/dev/null
grep $RUN_NAME SPECSummarizerDirectories.txt > /dev/null || echo $RUN_NAME >> SPECSummarizerDirectories.txt
summarizeIndividualFile > $RUN_NAME/$FILE_TO_READ.SPECSummarizerSummary.txt
echo "$RUN_NAME" > $OUTDIR/$RUN_NAME.$FILE_TO_READ
cat $FILE_TO_READ >> $OUTDIR/$RUN_NAME.$FILE_TO_READ
shift
done
echo "Benchmark,Baseline(Median),Baseline(Best),Baseline(Worst),Baseline(%Variance)" > $OUTDIR/FinalSPECSummary.csv
cat $(head -1 SPECSummarizerDirectories.txt)/* >> $OUTDIR/FinalSPECSummary.csv
# Combine all the individual summaries into one csv file
I=0
cat SPECSummarizerDirectories.txt | while read DIR
do
((I += 1))
if [ $I -eq 1 ]
then
continue
fi
# The first one is the baseline, skip it
echo Summarizing $DIR
addNamedSummary $DIR
done
# Add all the individual run summary files to the full summary
cat SPECSummarizerDirectories.txt | while read DIR
do
echo "$DIR" >> $OUTDIR/FinalSPECSummary.csv
echo "Benchmark,mean,best,worst,variance" >> $OUTDIR/FinalSPECSummary.csv
cat $DIR/* >> $OUTDIR/FinalSPECSummary.csv
done
# Clean up
rm -Rf $(cat SPECSummarizerDirectories.txt)
rm -f /tmp/summarize.cpp ./summarize ./CurrBenchRunTimes.txt SPECSummarizerDirectories.txt
echo "Result is in file $OUTDIR/FinalSPECSummary.csv"
################################SCRIPT ENDS#####################################
exit 0
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <vector>
#include <algorithm>
double getMedian(std::vector<double> &Vec) {
std::sort(Vec.begin(), Vec.end());
int Size = Vec.size();
if (!Size) return 0.;
if (Size % 2)
return Vec[Size/2];
return (Vec[Size/2] + Vec[Size/2-1]) / 2;
}
// Assume the vector is sorted at this point
double getVariance(const std::vector<double> &Vec, double Median) {
double Min = Vec[0];
double Max = Vec[Vec.size()-1];
return (Max - Min) / Median * 100.;
}
int main(int argc, const char **argv) {
if (argc < 4) {
fprintf(stderr, "Usage: %s [opt] <time1> <time2> [<time3>...]\n", argv[0]);
fprintf(stderr, " opt is one of -a or -d (for all or diff).\n");
fprintf(stderr, " The output for -a is: median,best,worst,variance.\n");
fprintf(stderr, " The output for -d is: ((time2-time1)/time1*100)%%.\n");
return 1;
}
// Computing the diff
if (!strcmp(argv[1], "-d")) {
double T1 = strtod(argv[2], NULL);
double T2 = strtod(argv[3], NULL);
printf("%.2f%%\n", (T2-T1)/T1*100);
return 0;
} else if (strcmp(argv[1], "-a")) {
fprintf(stderr, "Unrecognized option %s\n", argv[1]);
return 1;
}
std::vector<double> RTSet;
int i = 2;
for (; i < argc; i++) {
RTSet.push_back(strtod(argv[i], NULL));
}
double Median = getMedian(RTSet);
printf("%.4f,%.4f,%.4f,%.2f%%\n", Median, RTSet[0], RTSet[RTSet.size()-1],
getVariance(RTSet, Median));
return 0;
}
#!/usr/bin/env bash
if [[ -z "$3" ]] # here -z means: True if string is empty. from 'help test' doc
then
echo "Usage: $0 -o <DIR> Baseline:<SPEC.out.csv> [<NAME>:<SPEC.out.csv> ...]"
echo
echo "This script creates a csv file that contains a summary of multiple SPEC"
echo "run result csv files. The baseline is assumed to be the very first file"
echo "passed in."
echo "The -o option is mandatory and must appear prior to the list of files."
echo
echo "Sample invocation:"
echo "$0 -o Summaries Baseline:CINT2006.110.ref.csv \\"
echo " Baseline:CFP2006.110.ref.csv NoCRBits:CINT2006.112.ref.csv \\"
echo " NoCRBits:CFP2006.112.ref.csv CheapBR:CINT2006.111.ref.csv \\"
echo " CheapBR:CFP2006.111.ref.csv"
echo
echo "Implementation detail: For processing the inputs, the script will"
echo "create a directory for each of the named runs which it will clean"
echo "up after. If this directory happens to contain directories of the"
echo "same name, the script will prompt you before overwriting them."
exit 1
fi
###########################SCRIPT BEGINS ON LINE 78#############################
function summarizeBench {
SUMMARY=""
if [ $(cat CurrBenchRunTimes.txt | wc -l) -eq 1 ]
then
cat CurrBenchRunTimes.txt CurrBenchRunTimes.txt > tmpCurrBenchRunTimes.txt
mv tmpCurrBenchRunTimes.txt CurrBenchRunTimes.txt
fi
while read RT
do
SUMMARY="$SUMMARY $RT"
done < CurrBenchRunTimes.txt
echo $1,$($SUMMARIZE -a $SUMMARY)
}
function summarizeIndividualFile {
START=0
PREV_BENCH=""
while IFS=, read BENCH REF_T RUN_T RATIO REST
do
if [ "$BENCH" = Benchmark ]
then
START=1
continue
fi
if [ $START -ne 1 ]
then
continue
fi
if echo $REST | grep ',NR,' > /dev/null
then
continue
fi
if [[ -z "$BENCH" ]]
then
summarizeBench $PREV_BENCH
break
fi
if [ "$BENCH" = "$PREV_BENCH" ]
then
echo $RUN_T >> CurrBenchRunTimes.txt
else
if [[ -n "$PREV_BENCH" ]]
then
summarizeBench $PREV_BENCH
fi
PREV_BENCH=$BENCH
echo $RUN_T > CurrBenchRunTimes.txt
fi
done < $FILE_TO_READ
}
function addNamedSummary {
echo "$(head -1 $OUTDIR/FinalSPECSummary.csv),$1(Median),$1(Best),$1(Worst),$1(%Variance),$1(%Diff(Median)),$1(%Diff(Best)),$1(%Diff(Worst))" > tmpSPECSummarizer.txt
cat $1/* | while IFS=, read BENCH MEDIAN BEST WORST VARIANCE
do
BASE_LINE=$(grep ^$BENCH $OUTDIR/FinalSPECSummary.csv)
BASE_MEDIAN=$(echo $BASE_LINE | cut -f2 -d,)
BASE_BEST=$(echo $BASE_LINE | cut -f3 -d,)
BASE_WORST=$(echo $BASE_LINE | cut -f4 -d,)
DIFF_MEDIAN=$($SUMMARIZE -d $BASE_MEDIAN $MEDIAN)
DIFF_BEST=$($SUMMARIZE -d $BASE_BEST $BEST)
DIFF_WORST=$($SUMMARIZE -d $BASE_WORST $WORST)
echo $(grep ^$BENCH $OUTDIR/FinalSPECSummary.csv),$MEDIAN,$BEST,$WORST,$VARIANCE,$DIFF_MEDIAN,$DIFF_BEST,$DIFF_WORST
done >> tmpSPECSummarizer.txt
mv tmpSPECSummarizer.txt $OUTDIR/FinalSPECSummary.csv
}
function cleanupIfNeeded {
grep $RUN_NAME SPECSummarizerDirectories.txt > /dev/null
UNSEEN_DIR=$?
if [ $UNSEEN_DIR -ne 0 ]
then
echo $RUN_NAME >> SPECSummarizerDirectories.txt
ls $RUN_NAME > /dev/null 2>&1
if [ $? -eq 0 ]
then
echo "Directory $RUN_NAME already exists. Overwrite (Y/N)?"
read ANS<&1
if echo "$ANS" | grep -i ^y
then
echo Overwriting...
rm -Rf $RUN_NAME
else
exit 1
fi
fi
fi
}
################################SCRIPT BEGINS###################################
if [ "$1" != "-o" ]
then
echo "The -o option is mandatory as the first argument."
exit 1
fi
shift
OUTDIR=$1
shift
ls $OUTDIR > /dev/null 2>&1 || mkdir $OUTDIR
if [[ $? -ne 0 ]]
then
echo "Unable to create directory '$OUTDIR' that you specified as the output directory."
exit 1
fi
# Build the summarizer executable
if which summarize >/dev/null 2>&1
then
SUMMARIZE=$(which summarize)
else
START_AT=$(grep -n '^#include' $0 | head -1 | cut -f1 -d:)
END_AT=$(cat $0 | wc -l)
CPROG_LINES=$(expr $END_AT - $START_AT)
((CPROG_LINES += 1))
tail -$CPROG_LINES $0 > /tmp/summarize.cpp
g++ /tmp/summarize.cpp -o summarize
if [[ $? -ne 0 ]]
then
rm -f /tmp/summarize.cpp
exit 1
fi
SUMMARIZE=./summarize
fi
rm -f SPECSummarizerDirectories.txt 2>/dev/null
# Summarize each of the individual files and put the summaries in separate dirs
while [[ -n "$1" ]]
do
touch SPECSummarizerDirectories.txt
FILE_TO_READ=${1#*:}
RUN_NAME=${1%:*}
cleanupIfNeeded
mkdir $RUN_NAME 2>/dev/null
grep $RUN_NAME SPECSummarizerDirectories.txt > /dev/null || echo $RUN_NAME >> SPECSummarizerDirectories.txt
summarizeIndividualFile > $RUN_NAME/$FILE_TO_READ.SPECSummarizerSummary.txt
echo "$RUN_NAME" > $OUTDIR/$RUN_NAME.$FILE_TO_READ
cat $FILE_TO_READ >> $OUTDIR/$RUN_NAME.$FILE_TO_READ
shift
done
echo "Benchmark,Baseline(Median),Baseline(Best),Baseline(Worst),Baseline(%Variance)" > $OUTDIR/FinalSPECSummary.csv
cat $(head -1 SPECSummarizerDirectories.txt)/* >> $OUTDIR/FinalSPECSummary.csv
# Combine all the individual summaries into one csv file
I=0
cat SPECSummarizerDirectories.txt | while read DIR
do
((I += 1))
if [ $I -eq 1 ]
then
continue
fi
# The first one is the baseline, skip it
echo Summarizing $DIR
addNamedSummary $DIR
done
# Add all the individual run summary files to the full summary
cat SPECSummarizerDirectories.txt | while read DIR
do
echo "$DIR" >> $OUTDIR/FinalSPECSummary.csv
echo "Benchmark,mean,best,worst,variance" >> $OUTDIR/FinalSPECSummary.csv
cat $DIR/* >> $OUTDIR/FinalSPECSummary.csv
done
# Clean up
rm -Rf $(cat SPECSummarizerDirectories.txt)
rm -f /tmp/summarize.cpp ./summarize ./CurrBenchRunTimes.txt SPECSummarizerDirectories.txt
echo "Result is in file $OUTDIR/FinalSPECSummary.csv"
################################SCRIPT ENDS#####################################
exit 0
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <vector>
#include <algorithm>
double getMedian(std::vector<double> &Vec) {
std::sort(Vec.begin(), Vec.end());
int Size = Vec.size();
if (!Size) return 0.;
if (Size % 2)
return Vec[Size/2];
return (Vec[Size/2] + Vec[Size/2-1]) / 2;
}
// Assume the vector is sorted at this point
double getVariance(const std::vector<double> &Vec, double Median) {
double Min = Vec[0];
double Max = Vec[Vec.size()-1];
return (Max - Min) / Median * 100.;
}
int main(int argc, const char **argv) {
if (argc < 4) {
fprintf(stderr, "Usage: %s [opt] <time1> <time2> [<time3>...]\n", argv[0]);
fprintf(stderr, " opt is one of -a or -d (for all or diff).\n");
fprintf(stderr, " The output for -a is: median,best,worst,variance.\n");
fprintf(stderr, " The output for -d is: ((time2-time1)/time1*100)%%.\n");
return 1;
}
// Computing the diff
if (!strcmp(argv[1], "-d")) {
double T1 = strtod(argv[2], NULL);
double T2 = strtod(argv[3], NULL);
printf("%.2f%%\n", (T2-T1)/T1*100);
return 0;
} else if (strcmp(argv[1], "-a")) {
fprintf(stderr, "Unrecognized option %s\n", argv[1]);
return 1;
}
std::vector<double> RTSet;
int i = 2;
for (; i < argc; i++) {
RTSet.push_back(strtod(argv[i], NULL));
}
double Median = getMedian(RTSet);
printf("%.4f,%.4f,%.4f,%.2f%%\n", Median, RTSet[0], RTSet[RTSet.size()-1],
getVariance(RTSet, Median));
return 0;
}
Sunday, 19 March 2017
sed 文本替换利器
- 首处替换
sed 's/text/replace_text/' file //替换每一行的第一处匹配的text
- 全局替换
sed 's/text/replace_text/g' file
- 默认替换后,输出替换后的内容,如果需要直接替换原文件,使用-i:
sed -i 's/text/repalce_text/g' file
- 移除空白行 (here ^ 代表行头,$代表行尾):
sed '/^$/d' file
- 变量转换
已匹配的字符串通过标记&来引用.
$ echo this is a test line | sed 's/\w\+/[&]/g'
[this] [is] [a] [test] [line]
实际测试结果,并未加上[],需要调研原因:
$ echo this is en example | sed 's/\w+/[&]/g'
this is en example
$ echo this is en example | sed 's/\w+/[&]/g'
this is en example
- 子串匹配标记
第一个匹配的括号内容使用标记 \1 来引用
sed 's/hello\([0-9]\)/\1/'
- 双引号求值
sed通常用单引号来引用;也可使用双引号,使用双引号后,双引号会对表达式求值:
sed 's/$var/HLLOE/'
当使用双引号时,我们可以在sed样式和替换字符串中指定变量;
eg:
p=pattenr=replacedecho "line con a patten" | sed "s/$p/$r/g"$>line con a replaced
- 其它示例
字符串插入字符:将文本中每行内容(PEKSHA) 转换为 PEK/SHA
sed 's/^.\{3\}/&\//g' file
paste 按列拼接文本
将两个文本按列拼接到一起;
cat file112cat file2colinbookpaste file1 file21 colin2 book
默认的定界符是制表符,可以用-d指明定界符
paste file1 file2 -d ","
1,colin
2,book
Friday, 17 March 2017
performance analysis tool: Perf
Sampling with perf record
The perf tool can be used to collect profiles on per-thread, per-process and per-cpu basis.There are several commands associated with sampling: record, report, annotate. You must first collect the samples using perf record. This generates an output file called perf.data. That file can then be analyzed, possibly on another machine, using the perf report and perf annotate commands. The model is fairly similar to that of OProfile.
Thursday, 16 March 2017
Wednesday, 15 March 2017
STH/sth (Store Halfword)
Store Halfword D-form
sth RS,D(RA)
if RA = 0 then b .. 0
else b .. (RA)
EA .. b + EXTS(D)
MEM(EA, 2) .. (RS)48:63
Let the effective address (EA) be the sum (RA|0)+ D.
(RS)48:63 are stored into the halfword in storage
addressed by EA.
Special Registers Altered:
None
sth RS,D(RA)
if RA = 0 then b .. 0
else b .. (RA)
EA .. b + EXTS(D)
MEM(EA, 2) .. (RS)48:63
Let the effective address (EA) be the sum (RA|0)+ D.
(RS)48:63 are stored into the halfword in storage
addressed by EA.
Special Registers Altered:
None
Monday, 13 March 2017
How to use number expression when replacing in vim?
Here [0-9] will match any number, like local_unnamed_addr # 0, local_unnamed_addr # 1 ... local_unnamed_addr # 9 will all be replaced (here deleted actually)
:%s/local_unnamed_addr #[0-9]//gc
:%s/local_unnamed_addr #[0-9]//gc
LLVM test case update python script
Need to revisit this to understand it completely.
#!/usr/bin/env python2.7
"""A test case update script.
This script is a utility to update LLVM X86 'llc' based test cases with new
FileCheck patterns. It can either update all of the tests in the file or
a single test function.
"""
import argparse
import os # Used to advertise this file's name ("autogenerated_note").
import string
import subprocess
import sys
import re
# Invoke the tool that is being tested.
def llc(args, cmd_args, ir):
with open(ir) as ir_file:
stdout = subprocess.check_output(args.llc_binary + ' ' + cmd_args,
shell=True, stdin=ir_file)
# Fix line endings to unix CR style.
stdout = stdout.replace('\r\n', '\n')
return stdout
# RegEx: this is where the magic happens.
SCRUB_WHITESPACE_RE = re.compile(r'(?!^(| \w))[ \t]+', flags=re.M)
SCRUB_TRAILING_WHITESPACE_RE = re.compile(r'[ \t]+$', flags=re.M)
SCRUB_KILL_COMMENT_RE = re.compile(r'^ *#+ +kill:.*\n')
ASM_FUNCTION_X86_RE = re.compile(
r'^_?(?P<func>[^:]+):[ \t]*#+[ \t]*@(?P=func)\n[^:]*?'
r'(?P<body>^##?[ \t]+[^:]+:.*?)\s*'
r'^\s*(?:[^:\n]+?:\s*\n\s*\.size|\.cfi_endproc|\.globl|\.comm|\.(?:sub)?section)',
flags=(re.M | re.S))
SCRUB_X86_SHUFFLES_RE = (
re.compile(
r'^(\s*\w+) [^#\n]+#+ ((?:[xyz]mm\d+|mem)( \{%k\d+\}( \{z\})?)? = .*)$',
flags=re.M))
SCRUB_X86_SP_RE = re.compile(r'\d+\(%(esp|rsp)\)')
SCRUB_X86_RIP_RE = re.compile(r'[.\w]+\(%rip\)')
SCRUB_X86_LCP_RE = re.compile(r'\.LCPI[0-9]+_[0-9]+')
ASM_FUNCTION_ARM_RE = re.compile(
r'^(?P<func>[0-9a-zA-Z_]+):\n' # f: (name of function)
r'\s+\.fnstart\n' # .fnstart
r'(?P<body>.*?)\n' # (body of the function)
r'.Lfunc_end[0-9]+:\n', # .Lfunc_end0:
flags=(re.M | re.S))
RUN_LINE_RE = re.compile('^\s*;\s*RUN:\s*(.*)$')
TRIPLE_ARG_RE = re.compile(r'-mtriple=([^ ]+)')
TRIPLE_IR_RE = re.compile(r'^target\s+triple\s*=\s*"([^"]+)"$')
IR_FUNCTION_RE = re.compile('^\s*define\s+(?:internal\s+)?[^@]*@(\w+)\s*\(')
CHECK_PREFIX_RE = re.compile('--?check-prefix(?:es)?=(\S+)')
CHECK_RE = re.compile(r'^\s*;\s*([^:]+?)(?:-NEXT|-NOT|-DAG|-LABEL)?:')
ASM_FUNCTION_PPC_RE = re.compile(
r'^_?(?P<func>[^:]+):[ \t]*#+[ \t]*@(?P=func)\n'
r'\.Lfunc_begin[0-9]+:\n'
r'[ \t]+.cfi_startproc\n'
r'(?:\.Lfunc_[gl]ep[0-9]+:\n(?:[ \t]+.*?\n)*)*'
r'(?P<body>.*?)\n'
# This list is incomplete
r'(?:^[ \t]*(?:\.long[ \t]+[^\n]+|\.quad[ \t]+[^\n]+)\n)*'
r'.Lfunc_end[0-9]+:\n',
flags=(re.M | re.S))
def scrub_asm_x86(asm):
# Scrub runs of whitespace out of the assembly, but leave the leading
# whitespace in place.
asm = SCRUB_WHITESPACE_RE.sub(r' ', asm)
# Expand the tabs used for indentation.
asm = string.expandtabs(asm, 2)
# Detect shuffle asm comments and hide the operands in favor of the comments.
asm = SCRUB_X86_SHUFFLES_RE.sub(r'\1 {{.*#+}} \2', asm)
# Generically match the stack offset of a memory operand.
asm = SCRUB_X86_SP_RE.sub(r'{{[0-9]+}}(%\1)', asm)
# Generically match a RIP-relative memory operand.
asm = SCRUB_X86_RIP_RE.sub(r'{{.*}}(%rip)', asm)
# Generically match a LCP symbol.
asm = SCRUB_X86_LCP_RE.sub(r'{{\.LCPI.*}}', asm)
# Strip kill operands inserted into the asm.
asm = SCRUB_KILL_COMMENT_RE.sub('', asm)
# Strip trailing whitespace.
asm = SCRUB_TRAILING_WHITESPACE_RE.sub(r'', asm)
return asm
def scrub_asm_arm_eabi(asm):
# Scrub runs of whitespace out of the assembly, but leave the leading
# whitespace in place.
asm = SCRUB_WHITESPACE_RE.sub(r' ', asm)
# Expand the tabs used for indentation.
asm = string.expandtabs(asm, 2)
# Strip kill operands inserted into the asm.
asm = SCRUB_KILL_COMMENT_RE.sub('', asm)
# Strip trailing whitespace.
asm = SCRUB_TRAILING_WHITESPACE_RE.sub(r'', asm)
return asm
def scrub_asm_powerpc64le(asm):
# Scrub runs of whitespace out of the assembly, but leave the leading
# whitespace in place.
asm = SCRUB_WHITESPACE_RE.sub(r' ', asm)
# Expand the tabs used for indentation.
asm = string.expandtabs(asm, 2)
# Strip trailing whitespace.
asm = SCRUB_TRAILING_WHITESPACE_RE.sub(r'', asm)
return asm
# Build up a dictionary of all the function bodies.
def build_function_body_dictionary(raw_tool_output, triple, prefixes, func_dict,
verbose):
target_handlers = {
'x86_64': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'i686': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'x86': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'i386': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'arm-eabi': (scrub_asm_arm_eabi, ASM_FUNCTION_ARM_RE),
'powerpc64le': (scrub_asm_powerpc64le, ASM_FUNCTION_PPC_RE),
}
handlers = None
for prefix, s in target_handlers.items():
if triple.startswith(prefix):
handlers = s
break
else:
raise KeyError('Triple %r is not supported' % (triple))
scrubber, function_re = handlers
for m in function_re.finditer(raw_tool_output):
if not m:
continue
func = m.group('func')
scrubbed_body = scrubber(m.group('body'))
if func.startswith('stress'):
# We only use the last line of the function body for stress tests.
scrubbed_body = '\n'.join(scrubbed_body.splitlines()[-1:])
if verbose:
print >>sys.stderr, 'Processing function: ' + func
for l in scrubbed_body.splitlines():
print >>sys.stderr, ' ' + l
for prefix in prefixes:
if func in func_dict[prefix] and func_dict[prefix][func] != scrubbed_body:
if prefix == prefixes[-1]:
print >>sys.stderr, ('WARNING: Found conflicting asm under the '
'same prefix: %r!' % (prefix,))
else:
func_dict[prefix][func] = None
continue
func_dict[prefix][func] = scrubbed_body
def add_checks(output_lines, run_list, func_dict, func_name):
printed_prefixes = []
for p in run_list:
checkprefixes = p[0]
for checkprefix in checkprefixes:
if checkprefix in printed_prefixes:
break
if not func_dict[checkprefix][func_name]:
continue
# Add some space between different check prefixes.
if len(printed_prefixes) != 0:
output_lines.append(';')
printed_prefixes.append(checkprefix)
output_lines.append('; %s-LABEL: %s:' % (checkprefix, func_name))
func_body = func_dict[checkprefix][func_name].splitlines()
output_lines.append('; %s: %s' % (checkprefix, func_body[0]))
for func_line in func_body[1:]:
output_lines.append('; %s-NEXT: %s' % (checkprefix, func_line))
# Add space between different check prefixes and the first line of code.
# output_lines.append(';')
break
return output_lines
def should_add_line_to_output(input_line, prefix_set):
# Skip any blank comment lines in the IR.
if input_line.strip() == ';':
return False
# Skip any blank lines in the IR.
#if input_line.strip() == '':
# return False
# And skip any CHECK lines. We're building our own.
m = CHECK_RE.match(input_line)
if m and m.group(1) in prefix_set:
return False
return True
def main():
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('-v', '--verbose', action='store_true',
help='Show verbose output')
parser.add_argument('--llc-binary', default='llc',
help='The "llc" binary to use to generate the test case')
parser.add_argument(
'--function', help='The function in the test file to update')
parser.add_argument('tests', nargs='+')
args = parser.parse_args()
autogenerated_note = ('; NOTE: Assertions have been autogenerated by '
'utils/' + os.path.basename(__file__))
for test in args.tests:
if args.verbose:
print >>sys.stderr, 'Scanning for RUN lines in test file: %s' % (test,)
with open(test) as f:
input_lines = [l.rstrip() for l in f]
triple_in_ir = None
for l in input_lines:
m = TRIPLE_IR_RE.match(l)
if m:
triple_in_ir = m.groups()[0]
break
raw_lines = [m.group(1)
for m in [RUN_LINE_RE.match(l) for l in input_lines] if m]
run_lines = [raw_lines[0]] if len(raw_lines) > 0 else []
for l in raw_lines[1:]:
if run_lines[-1].endswith("\\"):
run_lines[-1] = run_lines[-1].rstrip("\\") + " " + l
else:
run_lines.append(l)
if args.verbose:
print >>sys.stderr, 'Found %d RUN lines:' % (len(run_lines),)
for l in run_lines:
print >>sys.stderr, ' RUN: ' + l
run_list = []
for l in run_lines:
commands = [cmd.strip() for cmd in l.split('|', 1)]
llc_cmd = commands[0]
triple_in_cmd = None
m = TRIPLE_ARG_RE.search(llc_cmd)
if m:
triple_in_cmd = m.groups()[0]
filecheck_cmd = ''
if len(commands) > 1:
filecheck_cmd = commands[1]
if not llc_cmd.startswith('llc '):
print >>sys.stderr, 'WARNING: Skipping non-llc RUN line: ' + l
continue
if not filecheck_cmd.startswith('FileCheck '):
print >>sys.stderr, 'WARNING: Skipping non-FileChecked RUN line: ' + l
continue
llc_cmd_args = llc_cmd[len('llc'):].strip()
llc_cmd_args = llc_cmd_args.replace('< %s', '').replace('%s', '').strip()
check_prefixes = [item for m in CHECK_PREFIX_RE.finditer(filecheck_cmd)
for item in m.group(1).split(',')]
if not check_prefixes:
check_prefixes = ['CHECK']
# FIXME: We should use multiple check prefixes to common check lines. For
# now, we just ignore all but the last.
run_list.append((check_prefixes, llc_cmd_args, triple_in_cmd))
func_dict = {}
for p in run_list:
prefixes = p[0]
for prefix in prefixes:
func_dict.update({prefix: dict()})
for prefixes, llc_args, triple_in_cmd in run_list:
if args.verbose:
print >>sys.stderr, 'Extracted LLC cmd: llc ' + llc_args
print >>sys.stderr, 'Extracted FileCheck prefixes: ' + str(prefixes)
raw_tool_output = llc(args, llc_args, test)
if not (triple_in_cmd or triple_in_ir):
print >>sys.stderr, "Cannot find a triple. Assume 'x86'"
build_function_body_dictionary(raw_tool_output,
triple_in_cmd or triple_in_ir or 'x86', prefixes, func_dict, args.verbose)
is_in_function = False
is_in_function_start = False
func_name = None
prefix_set = set([prefix for p in run_list for prefix in p[0]])
if args.verbose:
print >>sys.stderr, 'Rewriting FileCheck prefixes: %s' % (prefix_set,)
output_lines = []
output_lines.append(autogenerated_note)
for input_line in input_lines:
if is_in_function_start:
if input_line == '':
continue
if input_line.lstrip().startswith(';'):
m = CHECK_RE.match(input_line)
if not m or m.group(1) not in prefix_set:
output_lines.append(input_line)
continue
# Print out the various check lines here.
output_lines = add_checks(output_lines, run_list, func_dict, func_name)
is_in_function_start = False
if is_in_function:
if should_add_line_to_output(input_line, prefix_set) == True:
# This input line of the function body will go as-is into the output.
output_lines.append(input_line)
else:
continue
if input_line.strip() == '}':
is_in_function = False
continue
if input_line == autogenerated_note:
continue
# If it's outside a function, it just gets copied to the output.
output_lines.append(input_line)
m = IR_FUNCTION_RE.match(input_line)
if not m:
continue
func_name = m.group(1)
if args.function is not None and func_name != args.function:
# When filtering on a specific function, skip all others.
continue
is_in_function = is_in_function_start = True
if args.verbose:
print>>sys.stderr, 'Writing %d lines to %s...' % (len(output_lines), test)
with open(test, 'wb') as f:
f.writelines([l + '\n' for l in output_lines])
if __name__ == '__main__':
main()
#!/usr/bin/env python2.7
"""A test case update script.
This script is a utility to update LLVM X86 'llc' based test cases with new
FileCheck patterns. It can either update all of the tests in the file or
a single test function.
"""
import argparse
import os # Used to advertise this file's name ("autogenerated_note").
import string
import subprocess
import sys
import re
# Invoke the tool that is being tested.
def llc(args, cmd_args, ir):
with open(ir) as ir_file:
stdout = subprocess.check_output(args.llc_binary + ' ' + cmd_args,
shell=True, stdin=ir_file)
# Fix line endings to unix CR style.
stdout = stdout.replace('\r\n', '\n')
return stdout
# RegEx: this is where the magic happens.
SCRUB_WHITESPACE_RE = re.compile(r'(?!^(| \w))[ \t]+', flags=re.M)
SCRUB_TRAILING_WHITESPACE_RE = re.compile(r'[ \t]+$', flags=re.M)
SCRUB_KILL_COMMENT_RE = re.compile(r'^ *#+ +kill:.*\n')
ASM_FUNCTION_X86_RE = re.compile(
r'^_?(?P<func>[^:]+):[ \t]*#+[ \t]*@(?P=func)\n[^:]*?'
r'(?P<body>^##?[ \t]+[^:]+:.*?)\s*'
r'^\s*(?:[^:\n]+?:\s*\n\s*\.size|\.cfi_endproc|\.globl|\.comm|\.(?:sub)?section)',
flags=(re.M | re.S))
SCRUB_X86_SHUFFLES_RE = (
re.compile(
r'^(\s*\w+) [^#\n]+#+ ((?:[xyz]mm\d+|mem)( \{%k\d+\}( \{z\})?)? = .*)$',
flags=re.M))
SCRUB_X86_SP_RE = re.compile(r'\d+\(%(esp|rsp)\)')
SCRUB_X86_RIP_RE = re.compile(r'[.\w]+\(%rip\)')
SCRUB_X86_LCP_RE = re.compile(r'\.LCPI[0-9]+_[0-9]+')
ASM_FUNCTION_ARM_RE = re.compile(
r'^(?P<func>[0-9a-zA-Z_]+):\n' # f: (name of function)
r'\s+\.fnstart\n' # .fnstart
r'(?P<body>.*?)\n' # (body of the function)
r'.Lfunc_end[0-9]+:\n', # .Lfunc_end0:
flags=(re.M | re.S))
RUN_LINE_RE = re.compile('^\s*;\s*RUN:\s*(.*)$')
TRIPLE_ARG_RE = re.compile(r'-mtriple=([^ ]+)')
TRIPLE_IR_RE = re.compile(r'^target\s+triple\s*=\s*"([^"]+)"$')
IR_FUNCTION_RE = re.compile('^\s*define\s+(?:internal\s+)?[^@]*@(\w+)\s*\(')
CHECK_PREFIX_RE = re.compile('--?check-prefix(?:es)?=(\S+)')
CHECK_RE = re.compile(r'^\s*;\s*([^:]+?)(?:-NEXT|-NOT|-DAG|-LABEL)?:')
ASM_FUNCTION_PPC_RE = re.compile(
r'^_?(?P<func>[^:]+):[ \t]*#+[ \t]*@(?P=func)\n'
r'\.Lfunc_begin[0-9]+:\n'
r'[ \t]+.cfi_startproc\n'
r'(?:\.Lfunc_[gl]ep[0-9]+:\n(?:[ \t]+.*?\n)*)*'
r'(?P<body>.*?)\n'
# This list is incomplete
r'(?:^[ \t]*(?:\.long[ \t]+[^\n]+|\.quad[ \t]+[^\n]+)\n)*'
r'.Lfunc_end[0-9]+:\n',
flags=(re.M | re.S))
def scrub_asm_x86(asm):
# Scrub runs of whitespace out of the assembly, but leave the leading
# whitespace in place.
asm = SCRUB_WHITESPACE_RE.sub(r' ', asm)
# Expand the tabs used for indentation.
asm = string.expandtabs(asm, 2)
# Detect shuffle asm comments and hide the operands in favor of the comments.
asm = SCRUB_X86_SHUFFLES_RE.sub(r'\1 {{.*#+}} \2', asm)
# Generically match the stack offset of a memory operand.
asm = SCRUB_X86_SP_RE.sub(r'{{[0-9]+}}(%\1)', asm)
# Generically match a RIP-relative memory operand.
asm = SCRUB_X86_RIP_RE.sub(r'{{.*}}(%rip)', asm)
# Generically match a LCP symbol.
asm = SCRUB_X86_LCP_RE.sub(r'{{\.LCPI.*}}', asm)
# Strip kill operands inserted into the asm.
asm = SCRUB_KILL_COMMENT_RE.sub('', asm)
# Strip trailing whitespace.
asm = SCRUB_TRAILING_WHITESPACE_RE.sub(r'', asm)
return asm
def scrub_asm_arm_eabi(asm):
# Scrub runs of whitespace out of the assembly, but leave the leading
# whitespace in place.
asm = SCRUB_WHITESPACE_RE.sub(r' ', asm)
# Expand the tabs used for indentation.
asm = string.expandtabs(asm, 2)
# Strip kill operands inserted into the asm.
asm = SCRUB_KILL_COMMENT_RE.sub('', asm)
# Strip trailing whitespace.
asm = SCRUB_TRAILING_WHITESPACE_RE.sub(r'', asm)
return asm
def scrub_asm_powerpc64le(asm):
# Scrub runs of whitespace out of the assembly, but leave the leading
# whitespace in place.
asm = SCRUB_WHITESPACE_RE.sub(r' ', asm)
# Expand the tabs used for indentation.
asm = string.expandtabs(asm, 2)
# Strip trailing whitespace.
asm = SCRUB_TRAILING_WHITESPACE_RE.sub(r'', asm)
return asm
# Build up a dictionary of all the function bodies.
def build_function_body_dictionary(raw_tool_output, triple, prefixes, func_dict,
verbose):
target_handlers = {
'x86_64': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'i686': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'x86': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'i386': (scrub_asm_x86, ASM_FUNCTION_X86_RE),
'arm-eabi': (scrub_asm_arm_eabi, ASM_FUNCTION_ARM_RE),
'powerpc64le': (scrub_asm_powerpc64le, ASM_FUNCTION_PPC_RE),
}
handlers = None
for prefix, s in target_handlers.items():
if triple.startswith(prefix):
handlers = s
break
else:
raise KeyError('Triple %r is not supported' % (triple))
scrubber, function_re = handlers
for m in function_re.finditer(raw_tool_output):
if not m:
continue
func = m.group('func')
scrubbed_body = scrubber(m.group('body'))
if func.startswith('stress'):
# We only use the last line of the function body for stress tests.
scrubbed_body = '\n'.join(scrubbed_body.splitlines()[-1:])
if verbose:
print >>sys.stderr, 'Processing function: ' + func
for l in scrubbed_body.splitlines():
print >>sys.stderr, ' ' + l
for prefix in prefixes:
if func in func_dict[prefix] and func_dict[prefix][func] != scrubbed_body:
if prefix == prefixes[-1]:
print >>sys.stderr, ('WARNING: Found conflicting asm under the '
'same prefix: %r!' % (prefix,))
else:
func_dict[prefix][func] = None
continue
func_dict[prefix][func] = scrubbed_body
def add_checks(output_lines, run_list, func_dict, func_name):
printed_prefixes = []
for p in run_list:
checkprefixes = p[0]
for checkprefix in checkprefixes:
if checkprefix in printed_prefixes:
break
if not func_dict[checkprefix][func_name]:
continue
# Add some space between different check prefixes.
if len(printed_prefixes) != 0:
output_lines.append(';')
printed_prefixes.append(checkprefix)
output_lines.append('; %s-LABEL: %s:' % (checkprefix, func_name))
func_body = func_dict[checkprefix][func_name].splitlines()
output_lines.append('; %s: %s' % (checkprefix, func_body[0]))
for func_line in func_body[1:]:
output_lines.append('; %s-NEXT: %s' % (checkprefix, func_line))
# Add space between different check prefixes and the first line of code.
# output_lines.append(';')
break
return output_lines
def should_add_line_to_output(input_line, prefix_set):
# Skip any blank comment lines in the IR.
if input_line.strip() == ';':
return False
# Skip any blank lines in the IR.
#if input_line.strip() == '':
# return False
# And skip any CHECK lines. We're building our own.
m = CHECK_RE.match(input_line)
if m and m.group(1) in prefix_set:
return False
return True
def main():
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument('-v', '--verbose', action='store_true',
help='Show verbose output')
parser.add_argument('--llc-binary', default='llc',
help='The "llc" binary to use to generate the test case')
parser.add_argument(
'--function', help='The function in the test file to update')
parser.add_argument('tests', nargs='+')
args = parser.parse_args()
autogenerated_note = ('; NOTE: Assertions have been autogenerated by '
'utils/' + os.path.basename(__file__))
for test in args.tests:
if args.verbose:
print >>sys.stderr, 'Scanning for RUN lines in test file: %s' % (test,)
with open(test) as f:
input_lines = [l.rstrip() for l in f]
triple_in_ir = None
for l in input_lines:
m = TRIPLE_IR_RE.match(l)
if m:
triple_in_ir = m.groups()[0]
break
raw_lines = [m.group(1)
for m in [RUN_LINE_RE.match(l) for l in input_lines] if m]
run_lines = [raw_lines[0]] if len(raw_lines) > 0 else []
for l in raw_lines[1:]:
if run_lines[-1].endswith("\\"):
run_lines[-1] = run_lines[-1].rstrip("\\") + " " + l
else:
run_lines.append(l)
if args.verbose:
print >>sys.stderr, 'Found %d RUN lines:' % (len(run_lines),)
for l in run_lines:
print >>sys.stderr, ' RUN: ' + l
run_list = []
for l in run_lines:
commands = [cmd.strip() for cmd in l.split('|', 1)]
llc_cmd = commands[0]
triple_in_cmd = None
m = TRIPLE_ARG_RE.search(llc_cmd)
if m:
triple_in_cmd = m.groups()[0]
filecheck_cmd = ''
if len(commands) > 1:
filecheck_cmd = commands[1]
if not llc_cmd.startswith('llc '):
print >>sys.stderr, 'WARNING: Skipping non-llc RUN line: ' + l
continue
if not filecheck_cmd.startswith('FileCheck '):
print >>sys.stderr, 'WARNING: Skipping non-FileChecked RUN line: ' + l
continue
llc_cmd_args = llc_cmd[len('llc'):].strip()
llc_cmd_args = llc_cmd_args.replace('< %s', '').replace('%s', '').strip()
check_prefixes = [item for m in CHECK_PREFIX_RE.finditer(filecheck_cmd)
for item in m.group(1).split(',')]
if not check_prefixes:
check_prefixes = ['CHECK']
# FIXME: We should use multiple check prefixes to common check lines. For
# now, we just ignore all but the last.
run_list.append((check_prefixes, llc_cmd_args, triple_in_cmd))
func_dict = {}
for p in run_list:
prefixes = p[0]
for prefix in prefixes:
func_dict.update({prefix: dict()})
for prefixes, llc_args, triple_in_cmd in run_list:
if args.verbose:
print >>sys.stderr, 'Extracted LLC cmd: llc ' + llc_args
print >>sys.stderr, 'Extracted FileCheck prefixes: ' + str(prefixes)
raw_tool_output = llc(args, llc_args, test)
if not (triple_in_cmd or triple_in_ir):
print >>sys.stderr, "Cannot find a triple. Assume 'x86'"
build_function_body_dictionary(raw_tool_output,
triple_in_cmd or triple_in_ir or 'x86', prefixes, func_dict, args.verbose)
is_in_function = False
is_in_function_start = False
func_name = None
prefix_set = set([prefix for p in run_list for prefix in p[0]])
if args.verbose:
print >>sys.stderr, 'Rewriting FileCheck prefixes: %s' % (prefix_set,)
output_lines = []
output_lines.append(autogenerated_note)
for input_line in input_lines:
if is_in_function_start:
if input_line == '':
continue
if input_line.lstrip().startswith(';'):
m = CHECK_RE.match(input_line)
if not m or m.group(1) not in prefix_set:
output_lines.append(input_line)
continue
# Print out the various check lines here.
output_lines = add_checks(output_lines, run_list, func_dict, func_name)
is_in_function_start = False
if is_in_function:
if should_add_line_to_output(input_line, prefix_set) == True:
# This input line of the function body will go as-is into the output.
output_lines.append(input_line)
else:
continue
if input_line.strip() == '}':
is_in_function = False
continue
if input_line == autogenerated_note:
continue
# If it's outside a function, it just gets copied to the output.
output_lines.append(input_line)
m = IR_FUNCTION_RE.match(input_line)
if not m:
continue
func_name = m.group(1)
if args.function is not None and func_name != args.function:
# When filtering on a specific function, skip all others.
continue
is_in_function = is_in_function_start = True
if args.verbose:
print>>sys.stderr, 'Writing %d lines to %s...' % (len(output_lines), test)
with open(test, 'wb') as f:
f.writelines([l + '\n' for l in output_lines])
if __name__ == '__main__':
main()
Sunday, 12 March 2017
ORC/orc (OR with Complement)
OR with Complement X-form
orc RA,RS,RB (Rc=0)
orc. RA,RS,RB (Rc=1)
RA <= (RS) | ¬(RB)
The contents of register RS are ORed with the complement
of the contents of register RB and the result is
placed into register RA.
Special Registers Altered:
CR0 (if Rc=1)
orc RA,RS,RB (Rc=0)
orc. RA,RS,RB (Rc=1)
RA <= (RS) | ¬(RB)
The contents of register RS are ORed with the complement
of the contents of register RB and the result is
placed into register RA.
Special Registers Altered:
CR0 (if Rc=1)
Saturday, 11 March 2017
NOT Rx, ry <=> nor Rx,Ry,Ry
NOR X-form
nor RA,RS,RB (Rc=0)
nor. RA,RS,RB (Rc=1)
RA <= ¬((RS) | (RB))
The contents of register RS are ORed with the contents
of register RB and the complemented result is placed
into register RA.
Special Registers Altered:
CR0 (if Rc=1)
Extended Mnemonics:
Example of extended mnemonics for NOR:
Extended: Equivalent to:
not Rx,Ry nor Rx,Ry,Ry
nor RA,RS,RB (Rc=0)
nor. RA,RS,RB (Rc=1)
RA <= ¬((RS) | (RB))
The contents of register RS are ORed with the contents
of register RB and the complemented result is placed
into register RA.
Special Registers Altered:
CR0 (if Rc=1)
Extended Mnemonics:
Example of extended mnemonics for NOR:
Extended: Equivalent to:
not Rx,Ry nor Rx,Ry,Ry
Friday, 10 March 2017
Spec Reducer (sreducer)
66. How to reduce a spec test case?
Let us suppose there is a failure in h264ref benchmark.
Step1: create a build, link and run script
basically you need to create a script that just lists the compile commands,
the link command and the run command:
For example: I have a script named /home/jtony/tools/spec_reducer/buildLinkRun.sh
The build and link commands can be found by running the build.dry.sh script, this should
be run in your spec directory (like /home/jtony/scrum/s2/114/spec/cpu2006),
1(a): Here is my build command (part example):
cd /home/jtony/perf-runs/benchspec/CPU2006/464.h264ref/build/build_base_none.0000
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o annexb.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char
annexb.c &
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o biariencode.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char
biariencode.c &
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o block.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char b
lock.c &
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o cabac.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char c
abac.c &
...
1(b): Here is my link command:
/home/jtony/git-llvm/build/team-llvm//bin/clang -O2 -DSPEC_CPU_LINUX -fsigned-char annexb.o biariencode.o block.o cabac.o configfile.o context_ini.o decoder.o explicit_gop.o fast_me.o filehandle.o fmo.o header.o image.o intrarefresh.o leaky_bucket.o lencod.o loopFilter.o macroblock.o mb_access.o mbuffer.o memalloc.o mv-search.o nal.o nalu.o nalucommon.o output.o parset.o parsetcommon.o q_matrix.o q_offsets.o ratectl.o rdopt.o rdopt_coding_state.o rdpicdecision.o refbuf.o rtp.o sei.o slice.o transform8x8.o vlc.o weighted_prediction.o specrand.o -lm -m64 -Wl,-q -Wl,-rpath=/home/jtony/git-llvm/build/team-llvm//lib64 -o h264ref
1(c): the run command is a little bit harder to find, but you should be able to piece together the run
command from the speccmds.cmd file eg:
/home/jtony/perf-runs/temp/benchspec/CPU2006/464.h264ref/run/run_base_test_none.0000/speccmds.cmd
Here is the run command for my case:
cd /home/jtony/perf-runs/benchspec/CPU2006/464.h264ref/run/run_base_test_none.0000
/home/jtony/perf-runs/benchspec/CPU2006/464.h264ref/build/build_base_none.0000/h264ref -d foreman_test_encoder_baseline.cfg > tony.out
specperl /home/jtony/scrum/s2/114/spec/cpu2006/bin/specdiff -m -l 10 --cw --floatcompare /home/jtony/scrum/s2/114/spec/cpu2006/benchspec/CPU2006/464.h264ref/data/test/output/foreman_test_baseline_encodelog.out > tony.out
Step2, you need a good (no bug) and a bad (contains the bug) compiler. In my case, I have
The bad one /home/jtony/git-llvm/build/team-llvm/bin/clang++
The good one /home/jtony/git-llvm/build/good/bin/clang++
run this:
produceBinReduceScript.sh good_compiler bad_compiler, like:
/home/nemanjai/llvm/Git/llvm-on-power/utils/produceBinReduceScript.sh tony.sh /home/jtony/git-llvm/build/good/bin/clang /home/jtony/git-llvm/build/team-llvm/bin/clang
that produced `ReduceScript.sh`
Step3, once you have the ReduceScript, you can use binary search to find which file is miscompiled. In my case I have 43, you can do the following:
like
./ReduceScript.sh 1 43
./ReduceScript.sh 1 22
./ReduceScript.sh 11 22
./ReduceScript.sh 15 22
./ReduceScript.sh 18 22
./ReduceScript.sh 18 20
./ReduceScript.sh 18 19
./ReduceScript.sh 19 19
Step 4:
go into PPCISelDAGToDAG.cpp
and add:
`"#include "EnvDecider.hpp"`
and add:
#if 1
static EnvDecider RunMe("INSTANCE");
if (!(++RunMe))
return false;
#endif
Step 5:
then you can invoke the script like this (once you know how many there are):
`INSTANCE=1 ./ReduceScript.sh`
and so on and so forth
Let us suppose there is a failure in h264ref benchmark.
Step1: create a build, link and run script
basically you need to create a script that just lists the compile commands,
the link command and the run command:
For example: I have a script named /home/jtony/tools/spec_reducer/buildLinkRun.sh
The build and link commands can be found by running the build.dry.sh script, this should
be run in your spec directory (like /home/jtony/scrum/s2/114/spec/cpu2006),
1(a): Here is my build command (part example):
cd /home/jtony/perf-runs/benchspec/CPU2006/464.h264ref/build/build_base_none.0000
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o annexb.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char
annexb.c &
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o biariencode.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char
biariencode.c &
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o block.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char b
lock.c &
/home/jtony/git-llvm/build/team-llvm//bin/clang -c -o cabac.o -DSPEC_CPU -DNDEBUG -O2 -DSPEC_CPU_LINUX -fsigned-char c
abac.c &
...
1(b): Here is my link command:
/home/jtony/git-llvm/build/team-llvm//bin/clang -O2 -DSPEC_CPU_LINUX -fsigned-char annexb.o biariencode.o block.o cabac.o configfile.o context_ini.o decoder.o explicit_gop.o fast_me.o filehandle.o fmo.o header.o image.o intrarefresh.o leaky_bucket.o lencod.o loopFilter.o macroblock.o mb_access.o mbuffer.o memalloc.o mv-search.o nal.o nalu.o nalucommon.o output.o parset.o parsetcommon.o q_matrix.o q_offsets.o ratectl.o rdopt.o rdopt_coding_state.o rdpicdecision.o refbuf.o rtp.o sei.o slice.o transform8x8.o vlc.o weighted_prediction.o specrand.o -lm -m64 -Wl,-q -Wl,-rpath=/home/jtony/git-llvm/build/team-llvm//lib64 -o h264ref
1(c): the run command is a little bit harder to find, but you should be able to piece together the run
command from the speccmds.cmd file eg:
/home/jtony/perf-runs/temp/benchspec/CPU2006/464.h264ref/run/run_base_test_none.0000/speccmds.cmd
Here is the run command for my case:
cd /home/jtony/perf-runs/benchspec/CPU2006/464.h264ref/run/run_base_test_none.0000
/home/jtony/perf-runs/benchspec/CPU2006/464.h264ref/build/build_base_none.0000/h264ref -d foreman_test_encoder_baseline.cfg > tony.out
specperl /home/jtony/scrum/s2/114/spec/cpu2006/bin/specdiff -m -l 10 --cw --floatcompare /home/jtony/scrum/s2/114/spec/cpu2006/benchspec/CPU2006/464.h264ref/data/test/output/foreman_test_baseline_encodelog.out > tony.out
Step2, you need a good (no bug) and a bad (contains the bug) compiler. In my case, I have
The bad one /home/jtony/git-llvm/build/team-llvm/bin/clang++
The good one /home/jtony/git-llvm/build/good/bin/clang++
run this:
produceBinReduceScript.sh good_compiler bad_compiler, like:
/home/nemanjai/llvm/Git/llvm-on-power/utils/produceBinReduceScript.sh tony.sh /home/jtony/git-llvm/build/good/bin/clang /home/jtony/git-llvm/build/team-llvm/bin/clang
that produced `ReduceScript.sh`
Step3, once you have the ReduceScript, you can use binary search to find which file is miscompiled. In my case I have 43, you can do the following:
like
./ReduceScript.sh 1 43
./ReduceScript.sh 1 22
./ReduceScript.sh 11 22
./ReduceScript.sh 15 22
./ReduceScript.sh 18 22
./ReduceScript.sh 18 20
./ReduceScript.sh 18 19
./ReduceScript.sh 19 19
Step 4:
go into PPCISelDAGToDAG.cpp
and add:
`"#include "EnvDecider.hpp"`
and add:
#if 1
static EnvDecider RunMe("INSTANCE");
if (!(++RunMe))
return false;
#endif
Step 5:
then you can invoke the script like this (once you know how many there are):
`INSTANCE=1 ./ReduceScript.sh`
and so on and so forth
Thursday, 9 March 2017
findbadobjectfile script (learning)
#!/usr/bin/perl
@PURPOSE="Find bad compilation unit";
@SYNTAX="findbadobjectfile";
@NOTE="Uses scripts compileme, link.sh, and executeme. Also uses file object_names.";
# To use this script, create two directories: good_objects and bad_objects.
# Build the testcase twice. First build with good driver and move all the object files to good_objects directory.
# Build again with bad driver, and move all the object files to bad_objects directory.
# Create a script called link.sh which has the original link command. Remove all the object files from the link command.
# Create a file called object_names which lists all the object files, one per line.
# Create a script called executeme which runs the testcase and returns 0 for success.
sub link_program
{
print "***Running link cmd\n";
system("./temp_link.sh");
}
sub run_program
{
print "****Running program\n";
system("./executeme");
}
@obj_array = `cat object_names`;
use integer;
$lower = 0;
$size = @obj_array;
$upper = $size;
$lastgood = $size+1;
open (my $input, '<', 'link.sh');
$link = <$input>;
chomp ($link);
$j=0;
while( $lower < $upper-1 ) {
$link_cmd = $link;
my $link_file = "temp_link.sh";
open (my $fh, '>',$link_file) or die "Could not open $link_file";
system ("chmod +x temp_link.sh");
$middle = ($lower + $upper) / 2;
if($lower > 0){
for($i=0;$i<$lower;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " good_objects/".@obj_array[$i];
}
}
for($i=$lower;$i<$middle;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " good_objects/".@obj_array[$i];
}
for($i=$middle;$i<$upper;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " bad_objects/".@obj_array[$i];
}
if($upper < $size){
for($i=$upper;$i<$size;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " good_objects/".@obj_array[$i];
}
}
$link_cmd = $link_cmd."\n";
# print $link_cmd;
print $fh $link_cmd;
close $fh;
link_program;
run_program;
if($?==0){
print "Passed round $j\n";
$upper = $middle;
}else{
print "Failed round $j\n";
$lower = $middle;
}
$j=$j+1;
system("rm temp_link.sh");
}
print "Bad compilation unit: @obj_array[$lower]\n";
@PURPOSE="Find bad compilation unit";
@SYNTAX="findbadobjectfile";
@NOTE="Uses scripts compileme, link.sh, and executeme. Also uses file object_names.";
# To use this script, create two directories: good_objects and bad_objects.
# Build the testcase twice. First build with good driver and move all the object files to good_objects directory.
# Build again with bad driver, and move all the object files to bad_objects directory.
# Create a script called link.sh which has the original link command. Remove all the object files from the link command.
# Create a file called object_names which lists all the object files, one per line.
# Create a script called executeme which runs the testcase and returns 0 for success.
sub link_program
{
print "***Running link cmd\n";
system("./temp_link.sh");
}
sub run_program
{
print "****Running program\n";
system("./executeme");
}
@obj_array = `cat object_names`;
use integer;
$lower = 0;
$size = @obj_array;
$upper = $size;
$lastgood = $size+1;
open (my $input, '<', 'link.sh');
$link = <$input>;
chomp ($link);
$j=0;
while( $lower < $upper-1 ) {
$link_cmd = $link;
my $link_file = "temp_link.sh";
open (my $fh, '>',$link_file) or die "Could not open $link_file";
system ("chmod +x temp_link.sh");
$middle = ($lower + $upper) / 2;
if($lower > 0){
for($i=0;$i<$lower;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " good_objects/".@obj_array[$i];
}
}
for($i=$lower;$i<$middle;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " good_objects/".@obj_array[$i];
}
for($i=$middle;$i<$upper;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " bad_objects/".@obj_array[$i];
}
if($upper < $size){
for($i=$upper;$i<$size;$i++){
chomp(@obj_array[$i]);
$link_cmd = $link_cmd . " good_objects/".@obj_array[$i];
}
}
$link_cmd = $link_cmd."\n";
# print $link_cmd;
print $fh $link_cmd;
close $fh;
link_program;
run_program;
if($?==0){
print "Passed round $j\n";
$upper = $middle;
}else{
print "Failed round $j\n";
$lower = $middle;
}
$j=$j+1;
system("rm temp_link.sh");
}
print "Bad compilation unit: @obj_array[$lower]\n";
Subscribe to:
Posts (Atom)